
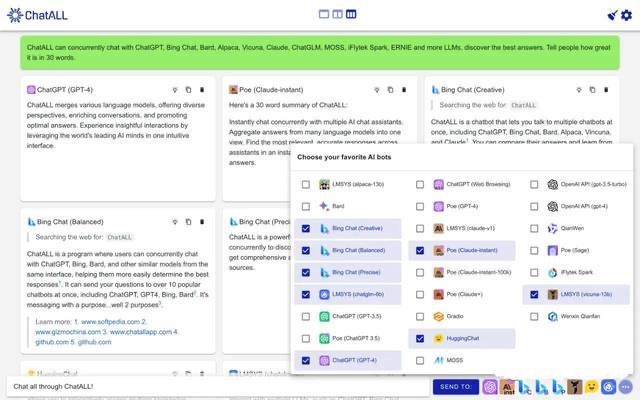
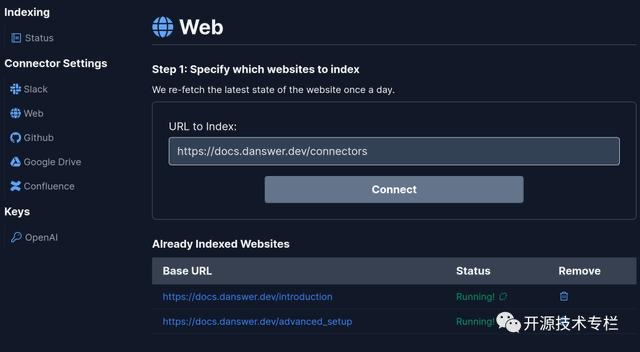
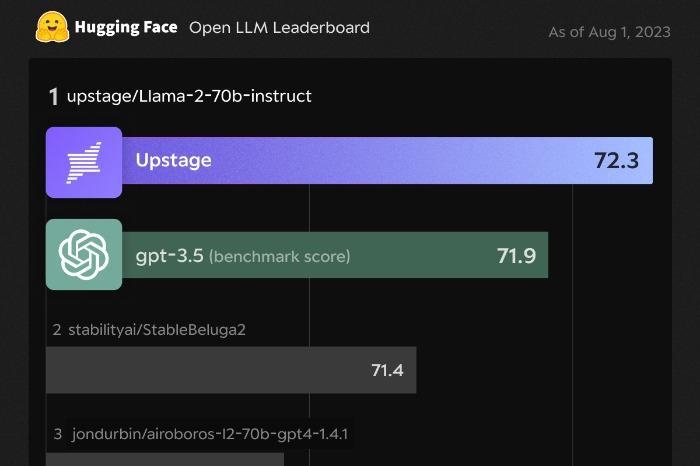
在上周,一个由硅谷创业极客和科研人员更新的播客Latent Space Podcast火了!
![图片[1]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fb345e9a6j00rypzqa00c5d200q800rcg00hx00io.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
两个小时的播客结束时,有接近2万人同时在收听。
后来组织者将他们的播客内容转录成一篇长文 ——《代码解释器就是GPT4.5》,在推特上获得了40万的阅读量。
文章非常全面地阐述了代码解释器的功能和它未来对OpenAI工作方向的影响。
他们甚至认为,代码解释器是一条通往AGI的高速公路!
不要在意版科技产品的版本号和名字
在技术领域,版本号大多是为了营销目的而存在,这已经是一个公开的秘密了。
Windows 3.0 跃迁至95版本是为了让公众感知到微软的重新设计(如今已成微软的标志)。
而且MacOS和Windows有意跳过了9版本,是为了吸引00后用户。
![图片[2]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fef079a50j00rypzqb009ld200nc00d6g00id00ac.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
那么我们应该如何理解大模型版本之间的关系呢?
理解版本号,对于科研人员来说,这可能是一个相对陌生的概念。
因为他们可能会轻松地训练400个不命名的语言模型来证实一个观点,但随着AI工程师在这些模型之上构建产品和业务的重要性日益增加,版本管理变得越来越重要了。
在生成式人工智能的简短历史中,我们有了一些案例可供参考。
GPT1→2→3 ,每一次更新都是明显的进步,而Midjourney 4→5则预示着Balenciaga Pope的到来。
![图片[3]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fe2efa308j00rypzqd00kzd200nc00fig00hx00bw.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
但类似 Stable Diffusion 1→2 的发展却引起了用户的争议。
小版本号理应是代表着某种意义上的升级。
它可能意味着从某一个基点开始,进行了更多的训练,比如 SD v1.3→1.4→1.5…
…这就引出了今天的话题,即GPT的.5版本号代表了很重要的改进。
应该大家还记得,GPT3.5紧跟着ChatGPT发布,并且包括了text-davinci-003和code-davinci-002。
这次更新完成了两个目标:
首先,让用户认识到GPT3.5相较于 GPT3(2020年的版本)优秀太多了。
![图片[4]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fb202ccdaj00rypzqe004td200u000fcg00id009d.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
原因是:
1. 增加了代码
2. 进行了指令 微调
3. RLHF/PPO
其次,表明这种新的聊天人机互动方式是通往AGI的未来之路。
我们对代码解释器认知的核心问题是:
1.让人们理解从GPT-4更新到代码解释器的影响到底有多大
2.讨论种新的范式是未来通往通用人工智能的方向
这两个特点导致我得出了一个结论:代码解释器应该被视为事实上的 GPT 4.5。
而且如果将来再加入API功能的话,我敢打赌,代码解释器结合起来就会被正式命名为 GPT 4.5。
那现在我们再稍微回顾一下代码解释器到底能干什么。
全面认识代码解释器
代码解释器是「一个实验性的ChatGPT模型」,可以将Python代码写入Jupyter Notebook并在Sandbox中执行,具有以下特点:
1. 与其他用户和互联网隔离的防火墙
2. 支持高达100MB的上传/下载(包括.csv、.xls、.png、.jpeg、.mov、.mp3、.epub、.pdf、.zip等整个Git存储库的文件)
3. 预装了超过330个库,如 pandas(数据分析)、matplotlib、seaborn、folium(图表和地图)、pytesseract(OCR)、Pillow(图像处理)、Pymovie(ffmpeg)、Scikit-Learn 和 PyTorch、Tensorflow(机器学习)
它本身是作为ChatGPT插件更新的一部分于3月23日官宣的,并由Andrew Mayne和Greg Brockman进行了专门的演示。
Alpha测持续了3个月。
最后,在7月6日至8日间,作为一项可选择的测试版功能向所有约200万的ChatGPT Plus用户推出。
![图片[5]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Feda7e7cbj00rypzqg005xd200u000gog00id00a7.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
由于这些功能可以在代码中灵活且无限地组合,很难完全列举出这个功能所有的潜力。
但通过示例学习(例如使用p5.js创建游戏、绘制表情包、创建交互式仪表板、数据预处理(包括季节性)、编写复杂的AST操作代码、大规模人脸检测,参见 Discord 上的 #code-interpreter-output 频道)并浏览库列表是很有帮助的。
![图片[6]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2F2de56930j00rypzqh00nqd200u000iqg00id00bg.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
Ethan Mollick提供了一些样本,他并不懂Python,但非常擅长从代码解释器中获取结果
Ethan还将他的经验总结为一份适用于代码解释器的系统提示。
代码解释器实际上引入了两个新的东西 – 沙盒和模型:
7月之前的大部分Alpha测试都是侧重于Python沙盒以及用户可以在沙盒里做什么,只是偶尔会用到自主编码的能力。
但在发布后,功能的重点变成了通过代码解释器所能提供的模型的质量上。
据传闻,它似乎比当今的GPT-4更好(在编写代码、自主进行多个步骤、决定何时不继续并要求用户在一组选项中进行选择方面)。
这个模型的自主性需要亲眼看到才能相信。以下是它在没有任何人类输入的情况下进行编码和调试的示例:
![图片[7]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fae8d497aj00rypzqk005qd200jz00r2g00id00ov.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
这种模型的进步之所以令人惊叹,是因为它将模型与模态性能够完美地结合在一起,就像之前的 ChatGPT 一样。
当然它也有一些缺点和限制:
1. 环境经常重置代码执行状态,丢失已上传的文件,并且其从故障中恢复的能力有限。
2. 它的OCR功能与GPT-4 Vision相去甚远。
3. 它会拒绝做它能做的事情,而你必须坚持让它做。
4. 它无法在代码中调用GPT3/4,因为它无法访问网络,因此无法执行诸如数据增强之类的任务,因为它试图编写解决问题的代码。
但抛开这些不足,总体来说,所有人对代码解释器的评价都是非常高的:
Karpathy:「代码解释器 Beta 功能非常强大。它是你的个人数据分析师:可以读取上传的文件、执行代码、生成图表、进行统计分析等等。我预计社区需要一些时间来充分发挥它的潜力。」
Simon Willison:「我开始使用Code Interprete后,它完成了我接下来两年的计划的所有任务。」
推理:大模型下一个最前沿的方向
在我们与George Hotz的对话之后,引发了一场关于OpenAI是否「没有创意」、GPT-4是否真的「只是8个220B专家模型」的讨论。
暂且不论像PanGu这样的万亿参数级模型的Routed Language Models和Switch Transformers的工作是否是真正的进步,代码解释器表明,只要不将进步的定义局限于纯粹的语言模型推理,仍然有提升的空间,并且OpenAI已经抓住了关键的这一点。
2017年,Noam Brown开发了Libratus,这是一个在12万次无限制德州扑克对决中击败了四名顶级职业选手的人工智能。
Noam Brown在Lex的访谈中谈到自己在这个项目中产生的最重要的一个想法:
![图片[8]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Ff97dc6b5j00rypzql00ard200r400f8g00id00ab.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
神经网络通常需要大约100毫秒的时间才能给出一个回答…但我们发现,如果你做一点搜索,就能使预先计算的策略(pre-computed strategy)扩大1000倍。而只需做一点搜索。就能使我们之前的所有研究都成了垃圾。
这个想法现在看起来是那么的显而易见:
-
在现实生活中,当面临一个更困难的问题时,人们会花更长时间思考,而不是面对一个更容易的问题。但是GPT3对于「一个球是圆的吗?」和「P = NP?」这样的问题几乎花费相同的时间来回答。那么,如果我们让它花上一年的时间呢?
-
我们已经看到Kojima著名的论文「让我们逐步思考」,通过允许模型在上下文中外化其思考过程并增加推理时间,就大大改善了语言模型的性能。Beam和Tree of Thought类型的搜索能够更有效地利用推理时间。
-
AI的每一个重大飞跃都源于某种能力的大量扩展(scaling)。Transformer 解锁了可并行预训练计算的能力。掩码语言建模(Masked Language Modeling)让我们可以处理大量的无标签数据。规模定律(Scaling Law)为我们提供了扩展模型规模的地图。似乎很明显,推理时间的计算/「实时的搜索」是下一个有希望的前沿防线,用Noam Brown的话来说「只需将时间话在上面就一定会有丰厚回报」。
Noam后来在2019年利用这个想法解决了6人德州扑克问题,然后在2022年利用这一见解解决了Diplomacy游戏(感谢了AlphaGo和AlphaZero的搜索算法)。
上个月,他仍在考虑这个问题:
![图片[9]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2F8618791fj00rypzqn006vd200el00i2g00id00mq.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
两周后,他加入了OpenAI。
代码生成、沙盒和智能体云(Agent Cloud)
我一直在强调 LLM 编码能力的特殊地位。
这是 AI 工程师崛起的重要推动因素。
这不仅仅是一个「噢,很可爱,Copilot 对开发人员有好处,但不太适合其他人」的故事 – LLM 代码是普遍有用的,即使对于不懂编程的人来说。
我所知道的关于「Code Core」的最早实验来自 Riley Goodside,他在去年在「你是GPT-3,你不能做数学」中展示了这一点。
这个实验第一次表明了,要弥补LLM的缺陷(如数学计算、与外部环境的交互、可解释性、速度/成本)的最佳方式是:
利用编写好的代码在LLM之外完成任务。
Nvidia的Voyager代理提供了将这一思路推向其逻辑结论的路线图:
![图片[10]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2F9ada0775j00rypzqp00bld200u000clg00id007p.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
当然,Voyager也存在一个明显的问题:现实世界比Minecraft更加随机,文档化程度更低,反馈周期更长。
就像Minion AI,Multion和AutoGPT一样,当前所有的智能体实例都可在实时浏览器/桌面上运行。
这使得潜在的幻觉和错误就是灾难性的,形成了就像「自动驾驶汽车中总是不得不把手放在方向盘上」一样的情况。
自从Ada Lovelace在Babbage Difference Engine存在之前就开始编写代码以来,开发人员就一直在用现实中的人群进行测试。
但最终,要知道代码是否可以运行并按预期执行,唯一的方法就是为其创建一个沙盒。(而代码解释器就能和用户一起创建无数个这样的沙盒)
大部分的代码生成/沙盒功能可以在本地完成。
但随着《本地主机的终结》(一篇讨论未来本地开发环境将会被云端开发环境取代的文章)中描述的情况越来越近。
越来越多的代理构建者和用户意识到构建和运行这些LLM推理过程的代码片段所需的云基础设施的需求。
我们可以合理地预未来代理云的兴起,以满足这一需求。
这实际上是一种新型的无服务器基础设施需求。
它不仅是临时的和可编程的,还将具备特殊的功能以提供必要的反馈给非人类操作者。
毫不奇怪,有一系列的可供选择的产品来适应这个新兴的代理云行业:
-
来自 Replit 的 Amjad 已经被公开讨论了
-
E2B 的Vasek拥有一个开源的Firecracker microVM实现
-
Codesandbox的Ives也有一个实现
-
Fly的Kurt在5月份推出了Fly Machines
你会注意到他们都使用了Firecracker,这个亚马逊在2018年开源的QEMU替代品微型虚拟机技术(对于一个通常不以开源软件领导者而闻名的公司来说,这是一个不错的胜利)。
然而,一个对比性的方法可能来自于Deno(在JavaScript领域)和Modal(在Python领域),它们的自动配置运行时提供了更轻量级的代理开发者和基础设施提供者之间的协议,但熟悉程度更低。
当然,OpenAI构建了自己的代理云,为200万用户提供托管和扩展代码解释器。
多年来,他们一直在使用这个技术,并且我们其他人才刚刚意识到它的重要性。
通往 GPT-5 的道路:代码增强推理
将所有这些综合起来,我们可以将代码解释器与先前的方法进行对比:
![图片[11]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2F448cc67cj00rypzqq0043d200u000ivg00hx00b9.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
就像上图列的一样,考虑到主要和次要版本升级的改进,考虑到代码解释器赋予了模型这么多的新能力,我认为代码解释器是「GPT 4.5」。
在我们的播客中,我们还会注意到,GPT4的重度使用者坚信GPT4基本版的质量已经有所下降(虽然OpenAI的Logan 声称服务的模型没有改变)。
这些粉丝同时也报告称,在没有编写代码的情况下,代码解释器的输出与原始的GPT4 在「削弱」之前的输出一样好。
假设这是真实的(很难证明,没有明确的代码解释器 API 来运行 lm-eval-harness),很可能是为了让代码解释器能够编写代码而进行的额外微调也改善了整体输出质量(这是我们从研究和Replit的经验,再考虑到GPT3.5本身的起源,即 code-davinci-002,所得到的结果)。
这使得代码解释器的基本模型,即使没有沙盒,从模型质量上来看也是「GPT 4.5」。
OpenAI的领先优势:
Sundar Pichai在6月份宣布了 Google Bard 的「代码执行」功能。
声称Bard可以执行简单的无依赖性的Python功能,比如数字相加和字符串反转。
![图片[12]-代码解释器等于GPT-4.5!-开放智能](https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2023%2F0802%2Fe7de2293j00rypzqq000zd200m800bog00id009n.jpg&thumbnail=960x2147483647&quality=75&type=jpg)
有趣的是,在一个月后我重新运行Google宣传时相同提示,发现完全用不了了!
与此同时,OpenAI正在推出一个全新的LLM编码范式。
OpenAI的领先优势令人难以置信!
参考资料:
https://www.latent.space/p/code-interpreter#details
















暂无评论内容